Big Data-based Identification and Mapping of Temporal Dynamics of Industrial Clusters
Project
This research aimed to develop an evidence based empirical framework for the identification and detection of evolution of industrial clusters over time. The framework aimed to explore how to transform times series of unstructured text descriptions of business activities using big data into industrial cluster dynamics. Combining data science techniques in topic modelling and web crawler technologies, we advanced the current best practices in four aspects: cost, objectivity, flexibility, and granularity. Clustering dynamic data can be generated on demand when policy demands arise. This is in contrast to the current practices of using firms' self-reported data in a predefined classification system, which is costly and time consuming to update. Using publicly available textual descriptions of business activities also offers a more direct inference about the underlying business activities, and the level of granularity is only bounded by the availability of data. The methodology contributes to the growing body of big data and business analytics research. It will provide the empirical foundations for advancing our understanding of the formation and dissolution of industrial clusters over time, and help advance the theoretical inquiry in the domain of economic geography.
Interactive Report
Project Outline
Background of research / Industrial clusters and policy
Industrial clustering has been an essential concept in industry intelligence and economic geography since Marshall (1920). Industrial clusters have been shown to foster learning and innovation across organisational settings and boundaries, through the agglomeration of economic activities, such as input-output linkages, labour market pooling, and knowledge spill-overs etc. Identifying and monitoring clusters can be a useful tool for policymakers, who can strategically support cluster formation and growth.
Extant methods of cluster detection rely mainly on standard industry classification systems. The purpose of such a coding system is to categorise businesses and other statistical units based on the types of economic activities they are engaged in. In the UK, the Standard Industrial Classification of Economic Activities is the most commonly used system. The government use this as a standard for clustering data and it promotes conformity. It is also widely used by non-government organisations for administrative purposes, as it provides a common structure for the classification of industrial activities. While historically the SIC system has served its purpose well, there are several characteristics of current practice that increasingly limit policymakers when making proactive and informed decisions.
-- Existing industry classification systems are subjective and compiled from expert opinions, rather than being dynamic and emerging from the direct inference of the underlying business activities. Similarly, the current way of classifying firms is based on self-reported data. Updating cluster data is costly and thus is done infrequently, and the classification system is largely static and inflexible when it comes to the changes needed.
-- The current system cannot differentiate between business activities that are similar, but not the same.
-- The design of the industry classification system aims at covering every manufacturing and service activity known with predefined categories, making the list very long. When organisations are asked to put themselves into any particular category, they may get very confused. Even smaller firms usually engage in more than one type of business activity.
-- To ensure completeness, the system has many generic categories such as ‘Business Services’. These are there to capture everything that firms cannot find a classification to fit in. When a firm cannot find an obvious category for its business activities, there is a natural tendency for it to place itself in one of these seemingly ‘catch all’ categories. For service businesses, especially those offering a wide range of services, knowledge-based firms, or in general organisations with a high level of consultancy content, this is particularly the case (Feldman et al, 2005). As innovation is picking up speed, so is the emergence of new business activities. Authorities have been trying to keep pace with this development and issue new SIC codes accordingly, but the pace of change has outpaced them.
Addressing the challenges
In this project we proposed a big data-analytic method to identify the temporal dynamics of industrial cluster evolution using open and web-based data. Our proposed approach had three distinct characteristics.
First, we utilised direct textual description about firms (their corporate websites). Thus, we avoided the need for firms to self-report in a fixed number of predefined industry classifications or categorise themselves in the ambiguous “other” category. As the data source is online and public, our approach is low-cost and the clusters identified can be updated as needed, in response to changes or other circumstances. The level of granularity is only bounded by the availability of data.
Second, our approach does not require manual input. The analysis was undertaken using advanced statistical learning techniques based on recent data science research. As such, no predefined industry classification was needed. This is a significant advantage over the current practice.
Thirdly, while a cross-sectional mapping of economic activities may be valuable, it offers little insight into the dynamics of cluster formation and their growth trajectories over time. Our method made it possible to capture such dynamics as well, thus significantly enhancing the model’s foresight value and in turn its capacity to underpin future policy .
Recommendations
In order to operationalise our approach on a wider scale and be able to use it reliably we recommend the following suggestions:
Cross sectional vs Longitudinal: An automated data collection system can not only make it possible to analyse data in a cross-sectional manner but also store it for longitudinal analysis at a later stage. This can ensure that limitations posed by archives such as the WayBack Machine can be overcome
Websites to be captured in annual corporate returns: This will make it possible to capture data more consistently, providing the list of addresses to scan.
Websites to have an activities.txt file similar to how they have robots.txt: Robots.txt is a file found in the root of a website, instructing search engines which areas not to crawl. Information about the products/services that a company offers could be appended to this file or a separate file called activities.txt. This will provide a list of keywords/descriptions in a structured manner. Crawling such files will be a far more efficient way than having to download, process and analyse web pages.
Extending the data set: In addition to website data, additional data sources (such as social media and company reports) could be used to extend the data set.
Clustering of smaller geographical units: Having a more representative and extended data set can offer an opportunity to make clustering of business activities at a more fine-grained level of regions, for example, more details on the 21 locales instead of the five bigger regions.
Reverse and focus the approach: Instead of clustering companies into groups, an alternative approach would be to scan for keywords representing a potential cluster of interest. This will show the dynamics of smaller groups of business activities across companies by analysing the keywords identified from the clustering stage. For example, within the technology cluster, emerging activities related keywords "5G" or "cloud" can be further analysed and highlighted.
Competitor analysis: Beyond obtaining insights into UK regions, there may be a case for examining regions internationally, which can offer both an opportunity to compare and benchmark activities. In addition to using wider sources of data a (www, social, news, etc) there will be a case for translating/corresponding clusters across languages.
Project Timeline
July 2020Webinar
The work was presented to ONS during a webinar and report submitted.
Juny 2020Analysis of data and refinements
Singificantly improved first set of results and optimised visualisations.
March / April / May 2020Data collection and Analysis
Extended data collection to cover the whole of the UK. Added new preprocessing steps. Improved the analysis.
February 2020Review of first complete process
We reviewed the methodology and considered the 1st set of results. Identification of refinements.
December 2019Visualisation and write up reports (v1)
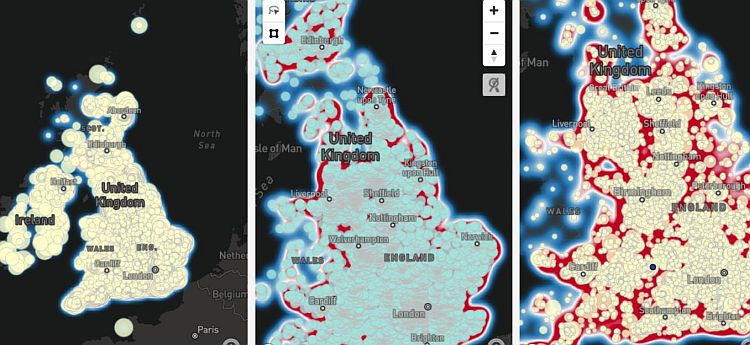
We used PowerBi to visualise the clusters cross-sectionally and longitudinally.
September / October 2019Analysis of data and refinements
We analysed the data longitudinaly exporting the clusters information and the list of companies per cluster.
June 2019July Data Collection
6 regions were selected for the downloading. The download featured up to 10 pages per company, on a quarterly basis from 2000 to 2019.
May 2019Draft data collection software and refined algorithm
The scale of the data collection and storage required adopting alternative to the originally-envisaged approaches.
April 2019Downloaded sample
UK and Irish companies with Turnover > £1.5 million, Profits > £150,000, Shareholder Funds > £1.5 million. 232k companies in 22 regions.
April 2019Project Commissioned
Project plan reviewed and milestones agreed.